About Me
Experienced Head of Data Science with over 20 years of combined academic and professional expertise, specializing in predictive modeling, data product development, and team leadership. Proficient in R, Python, and SQL with substantial experience in deploying data-driven solutions to enhance client decision-making in complex commodity markets. Demonstrates strong capabilities in statistical analysis, machine learning, and data visualization, facilitating effective collaboration across technical and non-technical teams.
- Time Series Forecasting
- Artificial Intelligence
- Machine Learning
- Applied Statistics
- Data Science
- Programming
-
Ph.D. Mathematical Statistics
University of Maryland
-
MA Economics
Universidade de Brasilia, Brazil
-
BSc Statistics
Universidade de Brasilia, Brazil
Experience
-
Regional Head of Data Science for Latin America
Argus MediaResponsibilities include:
- Established and currently manage the Latin American Data Science team, assembling a group of 12 professionals, including data engineers and scientists across three departments. Two of these departments are led by one department head and one team lead reporting directly to me.
- Enhanced project delivery efficiency by promoting a culture of innovation and collaboration, resulting in a notable team retention rate of 86% over nearly three years.
- Spearheaded the creation and deployment of R-based data products, enhancing client decision-making processes and operational efficiency by utilizing automation tools.
- Cultivated strategic partnerships with shareholders, driving the development of new analytical dashboards and products in R/Shiny, which led to an uplift in stakeholder engagement and product adoption.
- Collaborated with Business Developers and with the Sales team to design and present data science solutions to clients, enhancing the relevance and impact of presentations, which in turn spiked client interest and engagement.
- Provided expert guidance in statistical methods and time series analysis, significantly improving project outcomes and team skill levels.
- In charge of the daily production of the two principal data science products, ensuring the integrity of automated models and the accuracy of results prior to publication.
- Responsible for reviewing and approving changes to the code-base of the top revenue-generating data science product, instituting robust quality assurance protocols and enforcing strict version control with Git to enhance product reliability and performance.
-
Lecturer
University of MarylandResponsibilities include:
- Responsible for the development and delivery of a 400-level course in Computational Statistics, focusing on data wrangling, exploratory data analysis, and inferential statistics (including model building) using SAS© and SQL, directly contributing to the advancement of applied statistics and data science education.
- Designed and implemented cutting-edge evaluation strategies for a Computational Statistics course, incorporating data-backed research projects that required students to choose a topic, formulate their own research questions, and apply advanced statistical methods such as linear regression, logistic regression, or ANOVA.
- Emphasized the critical evaluation of methodological assumptions and coding accuracy, significantly enhancing students’ practical skills in data analysis and model interpretation, and preparing them for future careers as data scientists.
-
National Science Foundation (NSF) Mathematical Sciences Graduate Intern
Pacific Northwest National Laboratory - PNNLRead more about my experience on NSF's website (external link)Responsibilities include:
- Completed Coursera’s Deep Learning Specialization, covering from basics to CNNs & RNNs, demonstrating a solid foundation in AI/ML technologies critical for developing advanced data-driven solutions.
- Led the development and proposal of a RDBMS (PostgreSQL & MySQL) for a DOE, NETL, and PNNL project, showcasing leadership in managing tech projects and contributing to an increase in data processing efficiency by optimizing database architecture.
- Engineered a Python web crawler to extract relevant data for a PostgreSQL database, and spearheaded the development of a web application for experimental data input, achieving an improvement in data collection accuracy and efficiency.
- Led a workshop on R programming, focusing on ‘blogdown’ and ‘shiny’ packages, to an all-women audience, promoting diversity in tech and enhancing participants’ data analysis skills.
-
Principal Statistician
Brazilian Agency for Industrial Development (ABDI)Responsibilities include:
- Collaborated with a multidisciplinary team to analyze the impact of public policies (using simulation and quasi-experiment methods -difference in differences, propensity score matching -, and data visualization techniques) on Brazilian industrial development, delivering actionable insights and recommendations. This work was directly showcased through presentations to the Brazilian Minister of Industry.
- Spearheaded the collection and analysis of diverse socioeconomic data, driving data-driven decision-making and policy formulation. This role highlighted my project management and leadership skills, aligning with the competencies required for a Tech Lead Manager position.
- Managed data summarization and reporting processes, culminating in strategic recommendations that informed policy improvement initiatives, demonstrating a significant contribution to data-driven policy development.
- Worked with a team to developed a web enabled tool called The Competitiveness Decoder® that is focused on country data and has the goal of allowing users to learn and master the complexity related to competitiveness through different lenses. Find out more about it here. You can find me under “Former Team Members” on the website.
-
Lecturer
Universidade de Brasilia (UnB), BrazilResponsibilities include:
- Transformed the understanding of statistical models among undergraduate students from non-STEM backgrounds, achieving a marked improvement in their ability to apply data insights to diverse fields, as evidenced by enhanced course evaluations and increased student engagement.
- Pioneered innovative teaching methodologies to demystify complex statistical and machine learning concepts, fostering an interdisciplinary approach to data science education and preparing students for data-driven decision-making roles.
- Cultivated a collaborative educational environment that bridged the gap between technical and non-technical disciplines, significantly enhancing the interdisciplinary communication skills of students, as measured by their performance in team-based projects.
-
Statistical Consultant
Institute for Applied Economic Research (IPEA)Responsibilities include:
- Transformed the understanding of statistical models among undergraduate students from non-STEM backgrounds, achieving a marked improvement in their ability to apply data insights to diverse fields, as evidenced by enhanced course evaluations and increased student engagement.
- Pioneered innovative teaching methodologies to demystify complex statistical and machine learning concepts, fostering an interdisciplinary approach to data science education and preparing students for data-driven decision-making roles.
- Cultivated a collaborative educational environment that bridged the gap between technical and non-technical disciplines, significantly enhancing the interdisciplinary communication skills of students, as measured by their performance in team-based projects.
-
Operational Risk Management - Intern
Caixa Economica FederalResponsibilities include:
- Wrote advanced SAS macros to automate Value-at-Risk (VaR) calculations and predictions, utilizing convolutions and generalized extreme value distribution (GEV) to significantly enhance risk assessment efficiency by reducing system runtime.
- Led comprehensive database management and querying initiatives using SAS and SQL procedures, optimizing data retrieval processes and enhancing the accuracy of data-driven decision-making.
-
Junior Entrepreneur and Marketing Director
ESTAT ConsultoriaResponsibilities include:
- Pioneered the university’s first election poll under professorial supervision, establishing a foundation for subsequent academic inquiries.
- Delivered statistical consulting services to a diverse array of professionals, including sociologists, physicians, and musicians, enhancing their data interpretation and decision-making processes.
- Designed questionnaires and surveys for market research, focusing on optimizing data quality and reliability.
- Developed input masks using Microsoft Access and VBA to minimize data collection errors, ensuring higher accuracy in data analysis.
- Conducted research to refine management and advertising strategies, effectively driving business objectives and creating new opportunities.
Education
-
Ph.D. Mathematical Statistics
University of MarylandDissertation on Innovations In Time Series Forecasting: New Validation Procedures to Improve Forecasting Accuracy and A Novel Machine Learning Strategy for Model Selection. Supervised by Prof. Dr. Benjamin Kedem.Read dissertation -
MA Economics
Universidade de Brasilia, BrazilThesis on Impacts of the Brazilian science and technology sector funds on industrial firms’ R&D inputs and outputs: new perspectives using a dose-response function. Supervised by Prof. Dr. Donald Pianto. Won the brazilian Premio CNI de Economia in 2012.Read thesis -
BSc Statistics
Universidade de Brasilia, Brazil
Herbert A. Hauptman Fellowship
CNI National Economy Award (Prêmio CNI de Economia)
Project Management with Monday.com
Neural Networks and Deep Learning
Game Theory
Model Thinking
Project Management with Monday.com
Neural Networks and Deep Learning
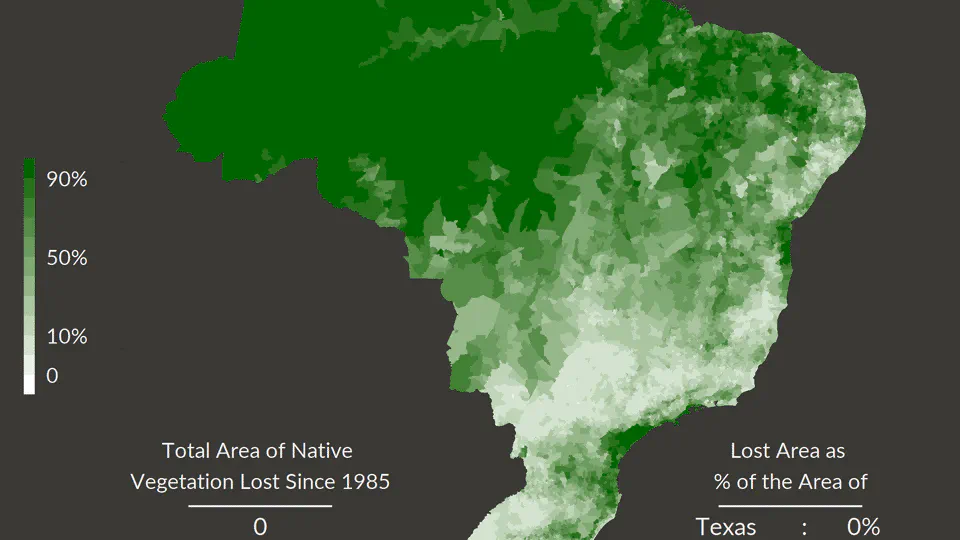
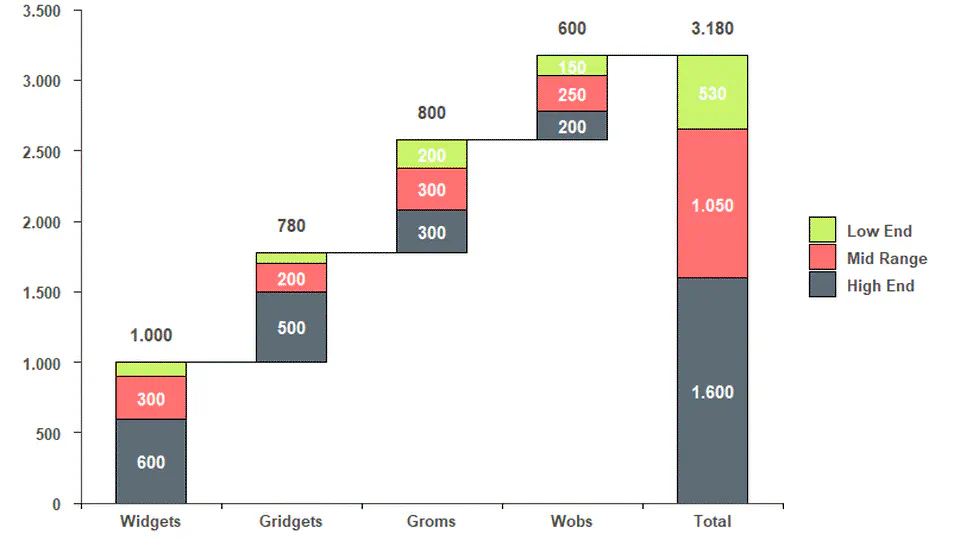
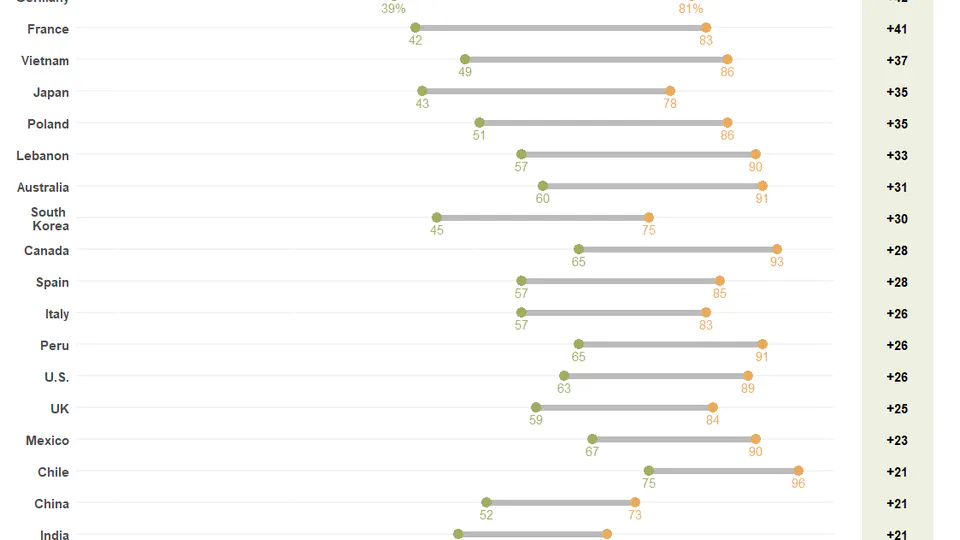
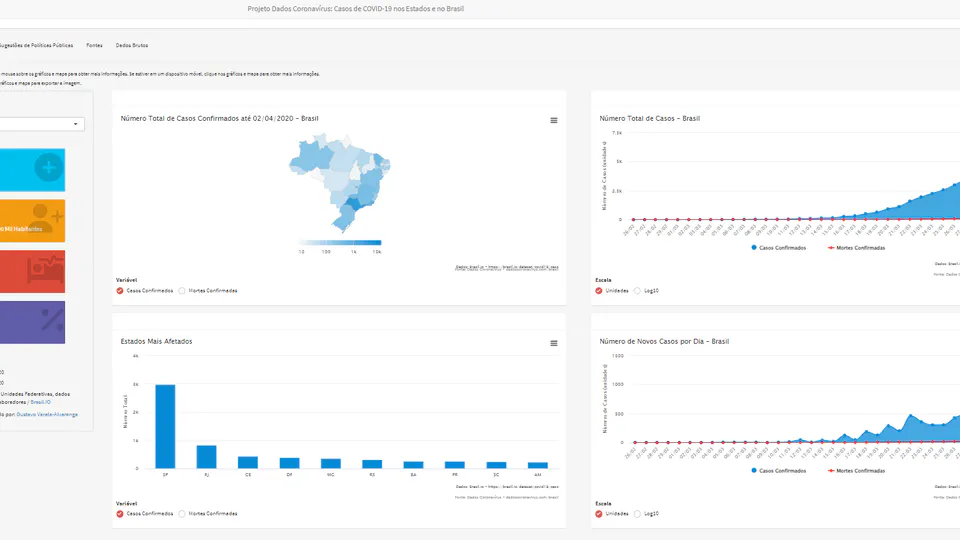
- Hitting times for Brownian Motion (2)
- How to define a rejection region?
- Why a sufficient statistic contains all the information needed to compute any estimate of the parameter?
- If rank(A)=k, can we say something about rank(AAt)?
- R package for motion capture data analysis and visualisation
- Transposing time series (mutate with lags) with dplyr
- Impact Evaluation
- Dataset cleaning
- Dataset Manipulation
- Research
- Econometric Analysis
- Quantitative and Qualitative Analysis
- Data Modeling
- Data Visualization
- Problem Solving
- Critical thinking
- Time Series Analysis
- Generalized Linear and Mixed Models
- ANOVA/MANOVA/ANCOVA
- Instrumental Variables Models
- Selection Models
- Matching Algorithms
- Hypothesis Testing
- Monte Carlo Simulations
- Bootstrap Methods
- Descriptive Statistics
- Survey design
- Experience with large datasets, including data from household surveys.
- Had to combine several datasets - with around 50 million lines each and 15 GB each - by an unique identification number.
- Used SQL procedures in SAS (PROC SQL) for data extraction and manipulation due to the size and complexity of the datasets.